FSDL 2022 project: 3D reconstruction
I recently completed the 2022 Full Stack Deep Learning course run by UC Berkeley Machine Learning PhD alumni. It was an excellent course in building ML products and the YouTube lectures are a great reference material for lot of topics, that I know I will revisit over the coming months. The final project for the course was to put the learnings into practice and build an ML powered application. I have been thinking a lot recently about ML applications in the field of domestic heating and energy efficiency as we are in the midst of a big energy crisis, inside a climate crisis, in the country in Europe with the leakiest homes. There is surely something to be done here.
I was struck by a tweet I saw from Skoon Energy recently, which shows a video demonstrating a product that enables users to scan their mobile phone camera (?) inside a home which generates a 3D reconstruction of the home. From this reconstruction, the user (presumably this is aimed at heating engineers) can compute the heat loss of the home, and recommend energy efficiency improvements or correct heat pump or boiler sizes. I thought that this was a great use of existing technology that could significantly speed up (and possibly improve) the existing, more manual, process.
I would have loved to have built something similar for the FSDL course, but only had four weeks of spare time outside of work and personal commitments to build something, so my ambitions had to be somewhat scaled back. I was browsing through Papers with Code and discovered a family of models that predict the 3D properties of a room from 2D panoramic image. This felt like a reasonable prototype to the type of product that I had seen, so decided to deploy it as a web application.
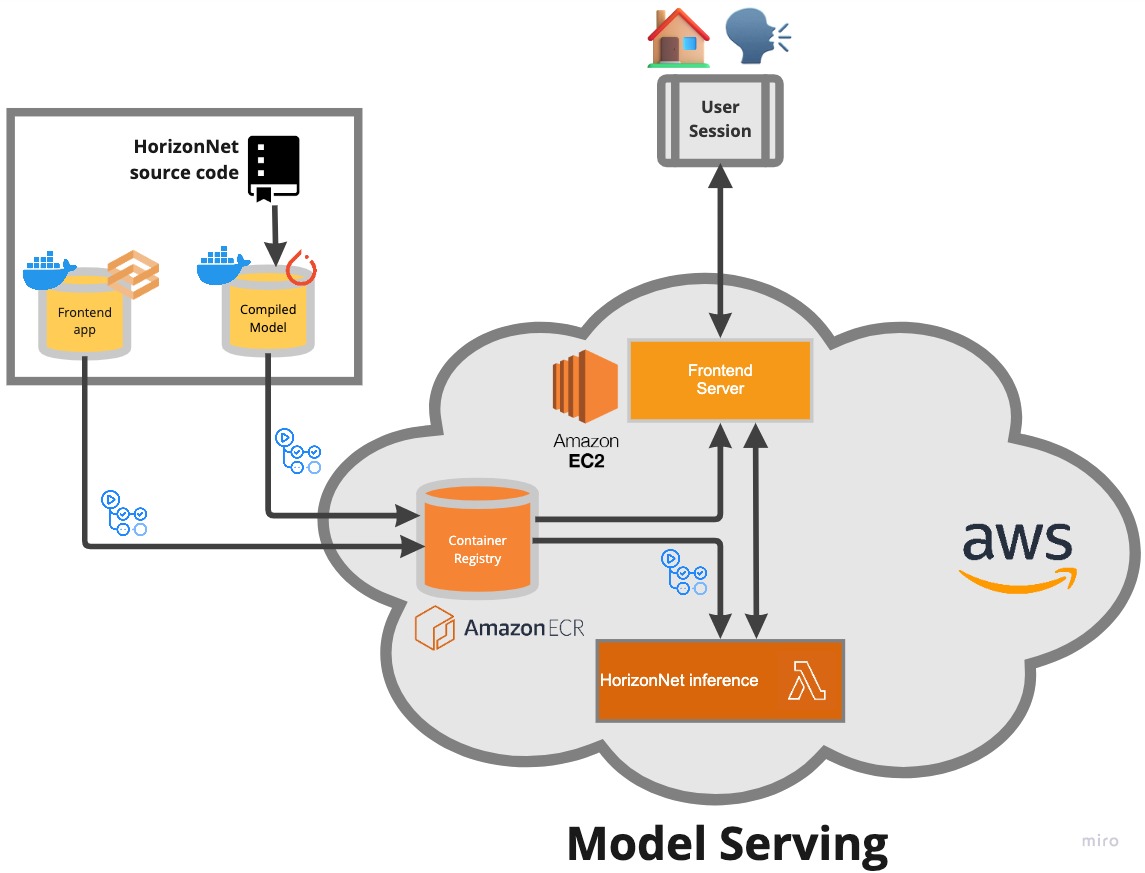
We reviewed the available papers and models, and found that HorizonNet was the state-of-the-art (SOTA), or at least the SOTA with open source code. To deploy this model there were three main steps. First we needed to serialise the model, which was taken care of with Torchscript making sure to refactor the code so that the inputs and outputs of the inference code were suitable for the web app we were planning to build. Next, we containerised the model with Docker, enabling us to deploy it on our chosen AWS environment. Finally we deployed it as an AWS Lambda function. I decided that it would be a good idea to try to automate the deployment steps as much as possible right from the start of the project, both to save time and as a way of not having to give my AWS password out to other team members! I used GitHub actions here to automatically push new versions of the model container code to AWS Elastic Container Registry and then updated our lambda function with this new container. I was impressed with how simple it was to set up this workflow, and this likely saved us many hours over the course of the project as we updated our Lambda function.
The other major task was to build a frontend app using Gradio, which we deployed to an EC2 instance. This was my first time using Gradio and was pretty impressed with how simple it was to set up a basic front end that enabled us to display 3D reconstructions of rooms. It was also relatively straightforward to communicate with the lambda function, so we faced few hiccups there. The hardest part was setting up the EC2 instance to work as a web application. It seemed more complicated that it needed to be to automatically deploy Docker containers on ECR to an EC2 instance, so instead opted to set up a GitHub action that automatically pushed new versions of the frontend Docker container to DockerHub, which I could then manually pull down to the EC2 instance and run fairly trivially.
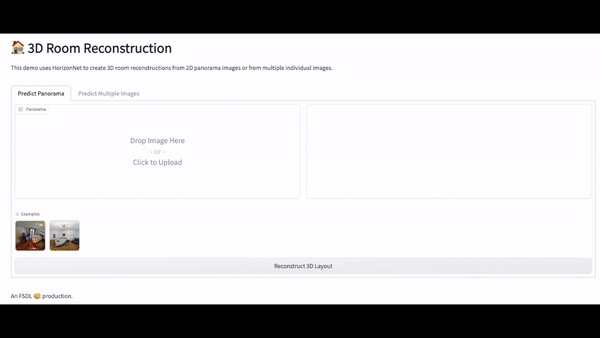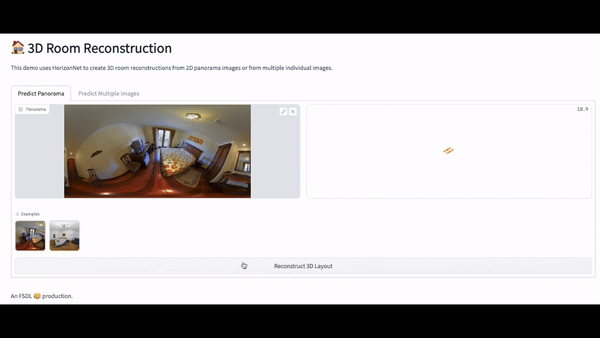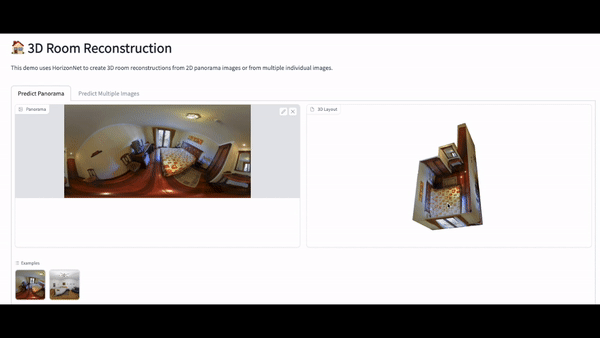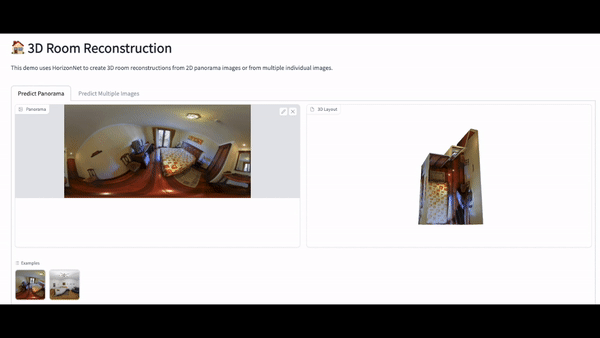
Once we had the app set up, the next step was to test the HorizonNet model with some out of sample data to see how it performed. We reached out to Matterport, who maintain a dataset of images inside homes, and they kindly gave us access to their dataset. We then ran some of these images through our app to see how our model performed. You can see some of these in the gifs below. Overall, the model seemed to perform pretty well on basic room layouts, but as complexity was added, for example wall partitions, glass and mirrors and outdoor elements, the model started to perform less well.
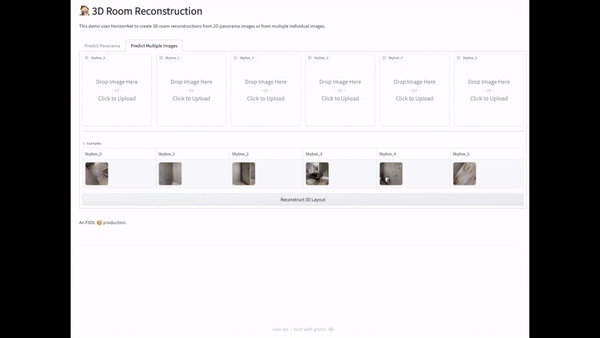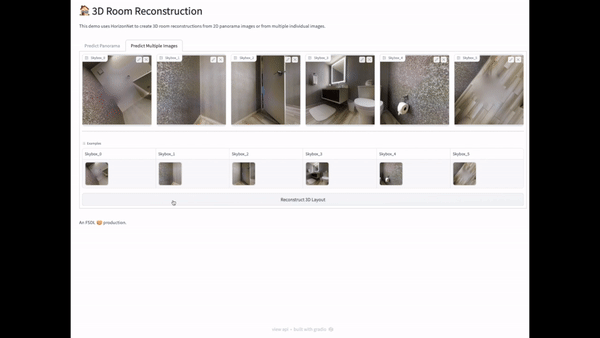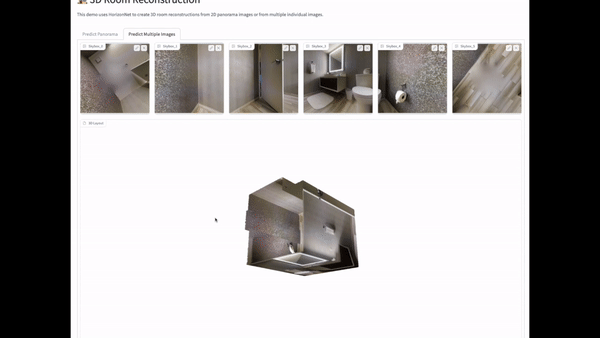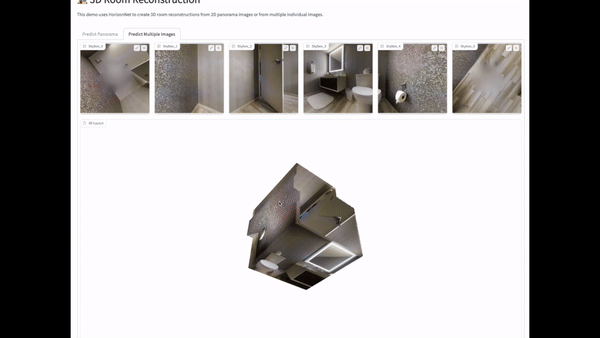
Given the limited time that we had for this project, there were many things we would have liked to have done if we had the time. First, it would have been great to be able to retrain the HorizonNet model on the additional data we received from Matterport to see if that would have improved performance. Unfortunately the labelling process is quite lengthy here so this was not something we had time for. Second, I would have like to add some basic tests, and fully automate the deployment process to make the development process for future versions as seamless as possible. Finally, I would have liked to play around with Gantry to set up some basic model monitoring. This would have allowed me to review images uploaded by users, detect drift and allow users to flag any poor predictions which could be reviewed offline.
There were a couple of things I would have done differently too. I tried to implement the philosophy of fast.ai and others to build the end-to-end application as quickly as possible and iterate from there. This approach speeds up the development process overall and brings lots of the tricky deployment questions up front at the start of the project, when energy levels are high and the time pressure is off. I think this approach worked well during this project, we got a simple version of an app up in days, albeit without the HorizonNet code. It did take us some time to figure out the API though. Previously I have designed APIs with Swagger and should have implemented something similar in this project, as there were some communication issues around what data the lambda function is expected to receive and send back to the front end. Sorting this out up front would have saved us some valuable time.
Overall though, this was a great experience in deploying an end-to-end machine learning model. I was able to use a few tools I had never had an opportunity to work with before: GitHub Actions, Gradio and Torchscript and it was fun to deploy a type of model I had never come across before this course. I would certainly recommend the FSDL course to anyone that is interested in build machine learning powered models - the course facilitators are very knowledgeable and the Discord server has been a great place to learn more about ML engineering.